"Hadoop" entries

Databricks aims to build next-generation analytic tools for Big Data
A new startup will accelerate the maturation of the Berkeley Data Analytics Stack
Key technologists behind the Berkeley Data Analytics Stack (BDAS) have launched a company that will build software – centered around Apache Spark and Shark – for analyzing big data. Details of their product and strategy are sparse, as the company is operating in stealth mode. But through conversations with the founders of Databricks, I’ve learned that they’ll be building general purpose analytic tools that can leverage HDFS, YARN, as well as other components of BDAS.
It will be interesting to see how the team transitions to the corporate world. Their Series A funding round of $14M is being led by Andreessen Horowitz. The board will be composed of Ben Horowitz, Scott Shenker, Matei Zaharia, and Ion Stoica.
Stream Processing and Mining just got more interesting
A general purpose stream processing framework from the team behind Kafka and new techniques for computing approximate quantiles
Largely unknown outside data engineering circles, Apache Kafka is one of the more popular open source, distributed computing projects. Many data engineers I speak with either already use it or are planning to do so. It is a distributed message broker used to store1 and send data streams. Kafka was developed by Linkedin were it remains a vital component of their Big Data ecosystem: many critical online and offline data flows rely on feeds supplied by Kafka servers.
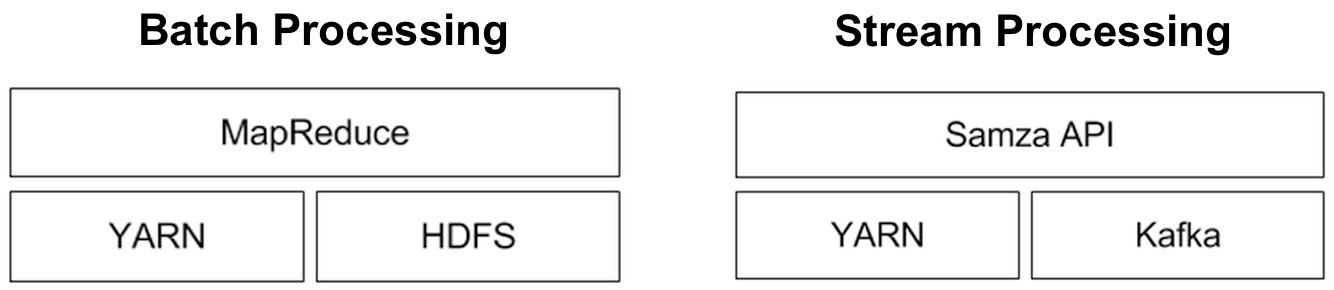
Apache Samza: a distributed stream processing framework
Behind Kafka’s success as an open source project is a team of savvy engineers who have spent2 the last three years making it a rock solid system. The developers behind Kafka realized early on that it was best to place the bulk of data processing (i.e., stream processing) in another system. Armed with specific use cases, work on Samza proceeded in earnest about a year ago. So while they examined existing streaming frameworks (such as Storm, S4, Spark Streaming), Linkedin engineers wanted a system that better fit their needs3 and requirements:

Working in the Hadoop Ecosystem
Working with big data and open source software
I recently sat down with Mark Grover (@mark_grover), a Software Engineer at Cloudera, to talk about the Hadoop ecosystem. He is a committer on Apache Bigtop and a contributor to Apache Hadoop, Hive, Sqoop, and Flume. He also contributed to O’Reilly Media’s Programming Hive title.
Key highlights include:
Running batch and long-running, highly available service jobs on the same cluster
Moving different workloads and frameworks onto the same collection of machines increases efficiency and ROI
As organizations increasingly rely on large computing clusters, tools for leveraging and efficiently managing compute resources become critical. Specifically, tools that allow multiple services and frameworks run on the same cluster can significantly increase utilization and efficiency. Schedulers1 take into account policies and workloads to match jobs with appropriate resources (e.g., memory, storage, processing power) in a large compute cluster. With the help of schedulers, end users begin thinking of a large cluster as a single resource (like “a laptop”) that can be used to run different frameworks (e.g., Spark, Storm, Ruby on Rails, etc.).
Multi-tenancy and efficient utilization translates into improved ROI. Google’s scheduler, Borg, has been in production for many years and has led to substantial savings2. The company’s clusters handle a variety of workloads that can be roughly grouped into batch (compute something, then finish) and services (web or infrastructure services like BigTable). Researchers recently examined traces from several Google clusters and observed that while “batch jobs” accounted for 80% of all jobs, “long service jobs” utilize 55-60% of resources.
There are other benefits of multi-tenancy. Being able to run analytics (batch, streaming) and long running services (e.g., web applications) on the same cluster significantly lowers latency3, opening up the possibility for real-time, analytic applications. Bake-offs can be done more effectively as competing tools, versions, and frameworks can be deployed on the same cluster. Data scientists and production engineers leverage the same compute resources, making it easier for teams to work together across the analytic lifecycle. An additional benefit is that data science teams learn to build products and services that factor in efficient utilization and availability.
Mesos, Chronos, and Marathon
Apache Mesos is a popular open source scheduler that originated from UC Berkeley’s AMPlab. Mesos is based on features in modern kernels for resource isolation (cgroups in Linux). It has been in production for a few years at Twitter4, airbnb5, and many other companies – AMPlab simulations showed Mesos comfortably handling clusters with 30K servers.
Interactive Big Data analysis using approximate answers
As data sizes continue to grow, interactive query systems may start adopting the sampling approach central to BlinkDB
Interactive query analysis for (Hadoop scale data) has recently attracted the attention of many companies and open source developers – some examples include Cloudera’s Impala, Shark, Pivotal’s HAWQ, Hadapt, CitusDB, Phoenix, Sqrrl, Redshift, and BigQuery. These solutions use distributed computing, and a combination of other techniques including data co-partitioning, caching (into main memory), runtime code generation, and columnar storage.
One approach that hasn’t been exploited as much is sampling. By this I mean employing samples to generate approximate answers, and speed up execution. Database researchers have written papers on approximate answers, but few working (downloadable) systems are actually built on this approach.
Approximate query engine from U.C. Berkeley’s Amplab
An interesting, open source database released yesterday0 uses sampling to scale to big data. BlinkDB is a massively-parallel, approximate query system from UC Berkeley’s Amplab. It uses a series of data samples to generate approximate answers. Users compose queries by specifying either error bounds or time constraints, BlinkDB uses sufficiently large random samples to produce answers. Because random samples are stored in memory1, BlinkDB is able to provide interactive response times:

Surfacing anomalies and patterns in Machine Data
Compelling large-scale data platforms originate from the world of IT Operations
I’ve been noticing that many interesting big data systems are coming out of IT operations. These are systems that go beyond the standard “capture/measure, display charts, and send alerts”. IT operations has long been a source of many interesting big data1 problems and I love that it’s beginning to attract the attention2 of many more data scientists and data engineers.
It’s not surprising that many of the interesting large-scale systems that target time-series and event data have come from ops teams: in an earlier post on time-series, several of the tools I highlighted came out of IT operations. IT operations involves monitoring many different hardware and software systems, a task that requires a variety of tools and which quickly leads to “metrics overload”. A partial list includes data captured from a wide range of application log files, network traffic, energy and power sources.
The volume of IT ops data has led to new tools like OpenTSDB and KairosDB – time series databases that leverage HBase and Cassandra. But storage, simple charts, and lookups are just the foundation of what’s needed. IT Ops track many interdependent systems, some of which might be correlated3. Not only are IT ops faced with highlighting “unknown unknowns” in their massive data sets, they often need to do so in near realtime.

Predicting the future: Strata 2014 hot topics
Eleven areas of focus for deeper investigation.
Conferences like Strata are planned a year in advance. The logistics and coordination required for an event of this magnitude takes a lot of planning, but it also takes a decent amount of prediction: Strata needs to skate to where the puck is going.
While Strata New York + Hadoop World 2013 is still a few months away, we’re already guessing at what next year’s Santa Clara event will hold. Recently, the team got together to identify some of the hot topics in big data, ubiquitous computing, and new interfaces. We selected eleven big topics for deeper investigation.
- Deep learning
- Time-series data
- The big data “app stack”
- Cultural barriers to change
- Design patterns
- Laggards and Luddites
- The convergence of two databases
- The other stacks
- Mobile data
- The analytic life-cycle
- Data anthropology
Here’s a bit more detail on each of them. Read more…

Why Choose a Graph Database
Collaborative filtering with Neo4j
By this time, chances are very likely that you’ve heard of NoSQL, and of graph databases like Neo4j.
NoSQL databases address important challenges that we face today, in terms of data size and data complexity. They offer a valuable solution by providing particular data models to address these dimensions.
On one side of the spectrum, these databases resolve issues for scaling out and high data values using compounded aggregate values, on the other side is a relationship based data model that allows us to model real world information containing high fidelity and complexity.
Neo4j, like many other graph databases, builds upon the property graph model; labeled nodes (for informational entities) are connected via directed, typed relationships. Both nodes and relationships hold arbitrary properties (key-value pairs). There is no rigid schema, but with node-labels and relationship-types we can have as much meta-information as we like. When importing data into a graph database, the relationships are treated with as much value as the database records themselves. This allows the engine to navigate your connections between nodes in constant time. That compares favorably to the exponential slowdown of many-JOIN SQL-queries in a relational database.

How can you use a graph database?
Graph databases are well suited to model rich domains. Both object models and ER-diagrams are already graphs and provide a hint at the whiteboard-friendliness of the data model and the low-friction mapping of objects into graphs.
Instead of de-normalizing for performance, you would normalize interesting attributes into their own nodes, making it much easier to move, filter and aggregate along these lines. Content and asset management, job-finding, recommendations based on weighted relationships to relevant attribute-nodes are some use cases that fit this model very well.
Many people use graph databases because of their high performance online query capabilities. They process large amounts or high volumes of raw data with Map/Reduce in Hadoop or Event-Processing (like Storm, Esper, etc.) and project the computation results into a graph. We’ve seen examples of this from many domains from financial (fraud detection in money flow graphs), biotech (protein analysis on genome sequencing data) to telco (mobile network optimizations on signal-strength-measurements).
Graph databases shine when you can express your queries as a local search using a few starting points (e.g., people, products, places, orders). From there, you can follow relevant relationships to accumulate interesting information, or project visited nodes and relationships into a suitable result.
Tightly integrated engines streamline Big Data analysis
A new set of analytic engines make the case for convenience over performance
The choice of tools for data science includes1 factors like scalability, performance, and convenience. A while back I noted that data scientists tended to fall into two camps: those who used an integrated stack, and others who tended to stitch together frameworks. Being able to stick with the same programming language and environment is a definite productivity boost since it requires less setup time and context-switching.
More recently I highlighted the emergence of composable analytic engines, that leverage data stored in HDFS (or HBase and Accumulo). These engines may not be the fastest available, but they scale to data sizes that cover most workloads, and most importantly they can operate on data stored in popular distributed data stores. The fastest and most complete set of algorithms will still come in handy, but I suspect that users will opt for slightly slower2, but more convenient tools, for many routine analytic tasks.

Get Hadoop, Hive, and HBase Up and Running in Less Than 15 Minutes
OSCON 2013 Speaker Series
If you have delved into Apache Hadoop and related projects, you know that installing and configuring Hadoop is hard. Often, a minor mistake during installation or configuration with messy tarballs will lurk for a long time until some otherwise innocuous change to the system or workload causes difficulties. Moreover, there is little to no integration testing among different projects (e.g. Hadoop, Hive, HBase, Zookeeper, etc.) in the ecosystem. Apache Bigtop is an open source project aimed at bridging exactly those gaps by:
1. Making it easier for users to deploy and configure Hadoop and related projects on their bare metal or virtualized clusters.
2. Performing integration testing among various components in the Hadoop ecosystem.
More about Apache Bigtop
The primary goal of Apache Bigtop is to build a community around the packaging and interoperability testing of Hadoop related projects. This includes testing at various levels (packaging, platform, runtime, upgrade, etc.) developed by a community with a focus on the system as a whole, rather than individual projects.
The latest released version of Apache Bigtop is Bigtop 0.5 which integrates the latest versions of various projects including Hadoop, Hive, HBase, Flume, Sqoop, Oozie and many more! The supported platforms include CentOS/RHEL 5 and 6, Fedora 16 and 17, SuSE Linux Enterprise 11, OpenSuSE 12.2, Ubuntu LTS Lucid and Precise, and Ubuntu Quantal.
Who uses Bigtop?
Folks who use Bigtop can be divided into two major categories. The first category of users are those who leverage Bigtop to power their own Hadoop Distributions. The second category of users are those who use Bigtop for deployment purposes.
In alphabetical order, they are:
Read more…