FEATURED STORY
Software engineers must continuously learn and integrate

These four themes will shape the programming world — and programming careers — in the months to come. Read more ...

This is why so many people have an opinion about design
With more companies focusing on design as a competitive advantage, it seems as if everyone is suddenly a designer.
Register now for OSCON EU, October 26 to 28, 2015, in Amsterdam, The Netherlands, where Tom Greever will present the session “Articulating design decisions.”
 The more that I talk to people about what it means to explain design, the more I realize that everyone across all types of organizations — from product companies to nonprofits to universities to health care — is intensely interested in it. Everyone now has an opinion about design, and we’ve all been in the position of having to defend our choices or suggestions.
The more that I talk to people about what it means to explain design, the more I realize that everyone across all types of organizations — from product companies to nonprofits to universities to health care — is intensely interested in it. Everyone now has an opinion about design, and we’ve all been in the position of having to defend our choices or suggestions.
Developers, product owners, project managers, and even CEOs are intimately involved in design processes now — increasingly, it seems as if everyone is a designer. But it hasn’t always been this way — so, why now do so many people have an opinion about design?
In the past decade, design and UX has gone “mainstream.” The most popular and interesting companies have put design at the forefront of their product offerings, creating a buzz culture that drools over every new release and a fan following that promotes their brand for them. I’m not only thinking of Apple, but also brands such as IKEA, innovators like Tesla, and unique problem-solving designs from Dyson, Segway, or Nest. These brands command respect, elicit strong opinions, and foster loyalty from the people who follow them. This elevation of design conversations within today’s companies , organizations, and throughout the public in general exemplifies a democratization of design that we haven’t before experienced.
Here, I’ll explore several factors contributing to design’s growing ubiquity.
Social media has changed how people view digital products
It’s not only physical products that have transformed our understanding of the value of design. Social media platforms have shown that UX is a critical component to success. Millions of people use Facebook every single day. Each minor tweak to the UI or change to the design incurs the praise or wrath of every user. Why? Because Facebook (and other services like it) is a very personal part of our lives. Never before have we had a platform for sharing the most intimate and mundane details of our everyday experiences. Read more…

Boost your career with new levels of automation
Elevate automation through orchestration.

As sysadmins we have been responsible for running applications for decades. We have done everything to meet demanding SLAs including “automating all the things” and even trading sleep cycles to recuse applications from production fires. While we have earned many battle scars and can step back and admire fully automated deployment pipelines, it feels like there has always been something missing. Our infrastructure still feels like an accident waiting to happen and somehow, no matter how much we manage to automate, the expense of infrastructure continues to increase.
The root of this feeling comes from the fact that many of our tools don’t provide the proper insight into what’s really going on and require us to reverse engineer applications in order to effectively monitor them and recover from failures. Today many people bolt on monitoring solutions that attempt to probe applications from the outside and report “health” status to a centralized monitoring system, which seems to be riddled with false alarms or a list of alarms that are not worth looking into because there is no clear path to resolution.
What makes this worse is how we typically handle common failure scenarios such as node failures. Today many of us are forced to statically assign applications to machines and manage resource allocations on a spreadsheet. It’s very common to assign a single application to a VM to avoid dependency conflicts and ensure proper resource allocations. Many of the tools in our tool belt have be optimized for this pattern and the results are less than optimal. Sure this is better than doing it manually, but current methods are resulting in low resource utilization, which means our EC2 bills continue to increase — because the more you automate, the more things people want to do.
How do we reverse course on this situation? Read more…

Contrasting architecture patterns with design patterns
How both kinds of patterns can add clarity and understanding to your project.
Developers are accustomed to design patterns, as popularized in the book Design Patterns by Gamma, et al. Each pattern describes a common problem posed in object-oriented software development along with a solution, visualized via class diagrams. In the Software Architecture Fundamentals workshop, Mark Richards & I discuss a variety of architecture patterns, such as Layered, Micro-Kernel, SOA, etc. However, architecture patterns differ from design patterns in several important ways.
Components rather than classes
Architectural elements tend towards collections of classes or modules, generally represented as boxes. Diagrams about architecture represent the loftiest level looking down, whereas class diagrams are at the most atomic level. The purpose of architecture patterns is to understand how the major parts of the system fit together, how messages and data flow through the system, and other structural concerns.
Architecture diagrams tend to be less rigidly defined than class diagrams. For example, many times the purpose of the diagram is to show one aspect of the system, and simple iconography works best. For example, one aspect of the Layered architecture pattern is whether the layers are closed (only accessible from the superior layer) or open (allowed to bypass the layer if no value added), as shown in Figure 1.
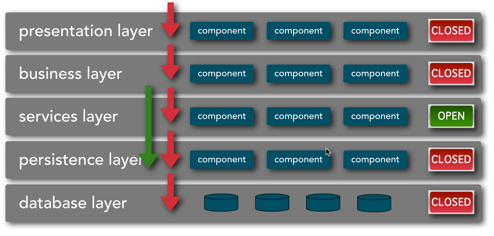
Figure 1: Layered architecture with mixed closed and open layers
This feature of the architecture isn’t the most important part, but is important to call out because if affects the efficacy of this pattern. For example, if developers violate this principle (e.g., performing queries from the presentation layer directly to the data layer), it compromises the separation of concerns and layer isolation that are the prime benefits of this pattern. Often an architectural pattern consists of several diagrams, each showing an important dimension.

Blocks in Ruby
A fundamental Ruby idiom explained.

When we talk about blocks in Ruby, we’re not usually talking about code blocks — or blocks of statements — as we might with other languages. We’re talking about a special syntax in Ruby, and one of its idioms. I’ll be discussing blocks in this article, plus a little about procs and lambdas.
Ruby’s blocks are always associated with methods, which are sets of recallable procedures. Blocks can’t get along very well by themselves. They are dependent on methods, which normally feed data to them. Without that data, a block can’t do anything useful. It needs a parent to look after it.
Blocks are anonymous and are sometimes referred to as nameless functions. Blocks are like methods within another method that grab data from an enclosing method. If all this is unfamiliar to you, it may not make sense. Keep reading and I’ll do my best to clear things up for you.

A developer’s introduction to 3D animation and Blender
An overview of the 3D animation process using Blender.
Creating 3D animations is like writing software. Both processes require
knowing certain industry terms. Some animation terms are:
- Modeling
- Texturing
- Rigging
- Setting up the scene with cameras, lights, and other effects
- Animating
- Rendering
Let’s define each of these, and then we’ll dig into some code with Blender’s API.
Modeling is the process of creating 3D models. One way is to represent the 3D model as points in 3D space. Each point, or vertex, has 3 coordinates: an X, an Y, and a Z coordinate, to define its location in 3D space. A pair of vertices can be connected by an edge, and edges bound polygons called faces. These faces define the surface of the model. Modeling is all about creating these sets of vertices, edges, and faces.
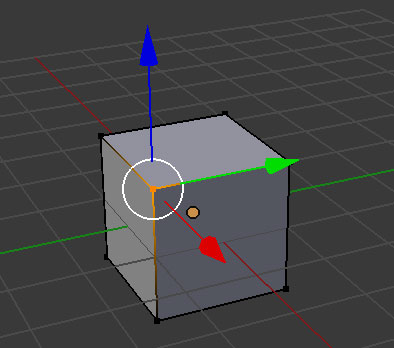
To create a model, we usually start with a primitive shape (like a sphere or a cube) and reshape it into what we’d like. Individual vertices, edges, and faces can be repositioned. New vertices, edges, and faces can be added to the basic model through simple operations. Two common ones are extrusion and subdivision.

Are there some students who can’t learn how to code?
Change tactics or give up: It's a crossroads many teachers face when students don't understand the code.
I can never forget an evening late into a semester of my Introduction to Python course, during which I asked my students a question about user-defined classes. Here’s the code I had put on the board:
class MyClass(object):
var = 0
def __init__(self): # called
MyClass.var = MyClass.var + 1
x = MyClass() # new instance created
y = MyClass() # new instance created
As new information for this particular lesson, I informed them that every time a new MyClass instance is created, the __init__() method is called implicitly. In other words, the code above calls __init__() twice, and in executing the code in __init__(), the variable MyClass.var is being incremented — so this is also happening twice.
So, I asked them: after the above code is executed, what is the value of MyClass.var?
The hand of this class’ most enthusiastic student shot into the air.
“One!” He answered proudly. And for a moment my mouth stood open. Read more…