"real time analytics" entries

Near realtime, streaming, and perpetual analytics
Hadoop moves from batch to near realtime: next up, placing streaming data in context
Simple example of a near realtime app built with Hadoop and HBase
Over the past year Hadoop emerged from its batch processing roots and began to take on interactive and near realtime applications. There are numerous examples that fall under these categories, but one that caught my eye recently is a system jointly developed by China Mobile Guangdong (CMG) and Intel1. It’s an online system that lets CMG’s over 100 million subscribers2 access and pay their bills, and examine their CDR’s (call detail records) in near realtime.
A service for providing detailed billing information is an important customer touch point. Repeated/extended downtimes and data errors could seriously tarnish CMG’s image. CMG needed a system that could scale to their current (and future) data volumes, while providing the low-latency responses consumers have come to expect from online services. Scalability, price and open source3 were important criteria in persuading the company to choose a Hadoop-based solution over4 MPP data warehouses.
In the system it co-developed with Intel, CMG stores detailed subscriber billing records in HBase. This amounts to roughly 30 TB/month, but since the service lets users browse up to six months of billing data it provides near realtime query results on much larger amounts of data. There are other near realtime applications built from Hadoop components (notably the continuous compute system at Yahoo!), that handle much larger data sets. But what I like about the CMG example is that it’s an application that most people understand right away (a detailed billing lookup system), and it illustrates that the Hadoop ecosystem has grown beyond batch processing.
Besides powering their online billing lookup service, CMG uses its Hadoop platform for analytics. Data from multiple sources (including phone device preferences, usage patterns, and cell tower performance) are used to compute customer segments and targeted promotions. Over time, Hadoop’s ability to handle large amounts of unstructured data opens up other data sources that can potentially improve CMG’s current analytic models.
Contextualize: Streaming and Perpetual Analytics
This leads me to something “realtime” systems are beginning to do: placing streaming data in context. Streaming analytics operates over fixed time windows and is used to identify “top k” trending items, heavy-hitters, and distinct items. Perpetual analytics takes what you’re observing now and places it in the context of what you already know. As much as companies appreciate metrics produced by streaming engines, they also want to understand how “realtime observations” affect their existing knowledge base.
Pattern-detection and Twitter’s Streaming API
In some key use cases a random sample of tweets can capture important patterns and trends
Researchers and companies who need social media data frequently turn to Twitter’s API to access a random sample of tweets. Those who can afford to pay (or have been granted access) use the more comprehensive feed (the firehose) available through a group of certified data resellers. Does the random sample of tweets allow you to capture important patterns and trends? I recently came across two papers that shed light on this question.
Systematic comparison of the Streaming API and the Firehose
A recent paper from ASU and CMU compared data from the streaming API and the firehose, and found mixed results. Let me highlight two cases addressed in the paper: identifying popular hashtags and influential users.
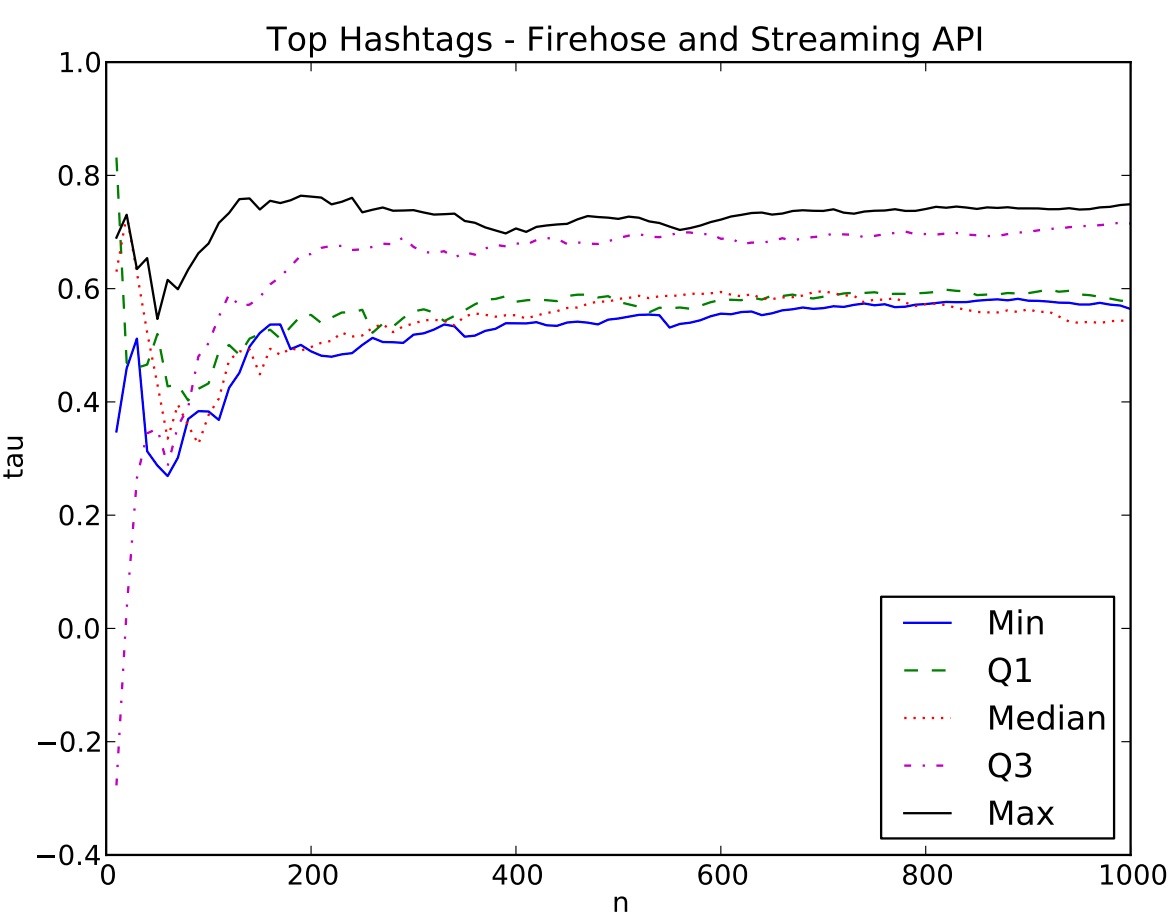
Of interest to many users is the list of top hashtags. Can one identify the “top n” hastags using data made available throughthe streaming API? The graph below is a comparison of the streaming API to the firehose: n (as in “top n” hashtags) vs. correlation (Kendall’s Tau). The researchers found that the streaming API provides a good list of hashtags when n is large, but is misleading for small n.
Moving from Batch to Continuous Computing at Yahoo!
Spark, Storm, HBase, and YARN power large-scale, real-time models.
My favorite session at the recent Hadoop Summit was a keynote by Bruno Fernandez-Ruiz, Senior Fellow & VP Platforms at Yahoo! He gave a nice overview of their analytic and data processing stack, and shared some interesting factoids about the scale of their big data systems. Notably many of their production systems now run on MapReduce 2.0 (MRv2) or YARN – a resource manager that lets multiple frameworks share the same cluster.
Yahoo! was the first company to embrace Hadoop in a big way, and it remains a trendsetter within the Hadoop ecosystem. In the early days the company used Hadoop for large-scale batch processing (the key example being, computing their web index for search). More recently, many of its big data models require low latency alternatives to Hadoop MapReduce. In particular, Yahoo! leverages user and event data to power its targeting, personalization, and other “real-time” analytic systems. Continuous Computing is a term Yahoo! uses to refer to systems that perform computations over small batches of data (over short time windows), in between traditional batch computations that still use Hadoop MapReduce. The goal is to be able to quickly move from raw data, to information, to knowledge:

On a side note: many organizations are beginning to use cluster managers that let multiple frameworks share the same cluster. In particular I’m seeing many companies – notably Twitter – use Mesos1 (instead of YARN) to run similar services (Storm, Spark, Hadoop MapReduce, HBase) on the same cluster.
Going back to Bruno’s presentation, here are some interesting bits – current big data systems at Yahoo! by the numbers:

On reading Mike Barlow’s “Real-Time Big Data Analytics: Emerging Architecture”
Barlow's distilled insights regarding the ever evolving definition of real time big data analytics

Reading Barlow on a Sunday afternoon
During a break in between offsite meetings that Edd and I were attending the other day, he asked me, “did you read the Barlow piece?”
“Umm, no.” I replied sheepishly. Insert a sidelong glance from Edd that said much without saying anything aloud. He’s really good at that.
In my utterly meager defense, Mike Loukides is the editor on Mike Barlow’s Real-Time Big Data Analytics: Emerging Architecture. As Loukides is one of the core drivers behind O’Reilly’s book publishing program and someone who I perceive to be an unofficial boss of my own choosing, I am not really inclined to worry about things that I really don’t need to worry about. Then I started getting not-so-subtle inquiries from additional people asking if I would consider reviewing the manuscript for the Strata community site. This resulted in me emailing Loukides for a copy and sitting in a local cafe on a Sunday afternoon to read through the manuscript.