- The 2016 Car Hacker’s Handbook (Amazon) — will give you a deeper understanding of the computer systems and embedded software in modern vehicles. It begins by examining vulnerabilities and providing detailed explanations of communications over the CAN bus and between devices and systems. (via BoingBoing)
- More Exoskeletons Seeking FDA Approval — The international group of exoskeleton providers with various FDA or CE certifications is growing and currently includes: Ekso in the US; Cyberdyne in the EU and Japan; ExoAtlet from Russia; and Israel’s ReWalk. Other providers are in the process of getting approvals or developing commercial versions of their products. My eye was caught by how global the list of exoskeleton companies is.
- Dirigible Spreadsheet — open source spreadsheet that’s not just written in Python, it exposes and IS python. See also Harry Percival talking about it.
- Everything You Know About AI Is Wrong (Gizmodo) — an interesting run-through of myths and claims about AI. I’m not ready to consider all of these “busted,” but they are some nice starters-for-ten in your next pub argument about whether the Matrix is coming.
"Python" entries

Four short links: 15 March 2016
Car Hackers Handbook, Exoskeleton Regulation, Pythonic Spreadsheet, and AI Myths
Four short links: 8 February 2016
Experimental Support, Coding Books, Bad Decisions, and GitHub to Jupyter
- Elemental Machines — Boston startup fitting experiments & experimenters with sensors, deep learning to identify problems (vibration, humidity, etc.) that could trigger experimental failure. [C]rucial experiments are often delayed by things that seem trivial in retrospect. “I talked to my friends who worked in labs,” Iyengar says. “Everyone had a story to tell.” One scientist’s polymer was unstable because of ultraviolet light coming through a nearby window, he says; that took six months to debug. Another friend who worked at a pharmaceutical company was testing drug candidates in mice. The results were one failure after another, for months, until someone figured out that the lab next door was being renovated, and after-hours construction was keeping the mice awake and stressing them out. (that quote from Xconomy)
- Usborne Computer and Coding Books — not only do they have sweet Scratch books for kids, they also have their nostalgia-dripping 1980s microcomputer books online. I still have a pile of my well-loved originals.
- Powerful People are Terrible at Making Decisions Together — Researchers from the Haas School of Business at the University of California, Berkeley, undertook an experiment with a group of health care executives on a leadership retreat. They broke them into groups, presented them with a list of fictional job candidates, and asked them to recommend one to their CEO. The discussions were recorded and evaluated by independent reviewers. The higher the concentration of high-ranking executives, the more a group struggled to complete the task. They competed for status, were less focused on the assignment, and tended to share less information with each other.
- MyBinder — turn a GitHub repo into a collection of interactive notebooks powered by Jupyter and Kubernetes.
Four short links: 29 October 2015
Cloud Passports, Better Python Notebooks, Slippery Telcos, and Python Data Journalism
- Australia Floating the Idea of Cloud Passports — Under a cloud passport, a traveller’s identity and biometrics data would be stored in a cloud, so passengers would no longer need to carry their passports and risk having them lost or stolen. That sound you hear is Taylor Swift on Security, quoting “Wildest Dreams” into her vodka and Tang: “I can see the end as it begins.” This article is also notable for The idea of cloud passports is the result of a hipster-style-hackathon.
- Jupyter — Python Notebooks that allows you to create and share documents that contain live code, equations, visualizations, and explanatory text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, machine learning, and much more.
- Telcos $24B Business In Your Data — Under the radar, Verizon, Sprint, Telefonica, and other carriers have partnered with firms including SAP, IBM, HP, and AirSage to manage, package, and sell various levels of data to marketers and other clients. It’s all part of a push by the world’s largest phone operators to counteract diminishing subscriber growth through new business ventures that tap into the data that showers from consumers’ mobile Web surfing, text messaging, and phone calls. Even if you do pay for it, you’re still the product.
- Introducing Agate — a Python data analysis library designed to be useable by non-data-scientists, so leads to readable and predictable code. Target market: data journalists.

A developer’s introduction to 3D animation and Blender
An overview of the 3D animation process using Blender.
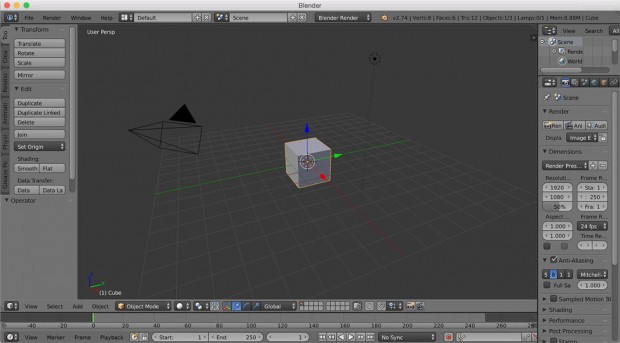
Creating 3D animations is like writing software. Both processes require
knowing certain industry terms. Some animation terms are:
- Modeling
- Texturing
- Rigging
- Setting up the scene with cameras, lights, and other effects
- Animating
- Rendering
Let’s define each of these, and then we’ll dig into some code with Blender’s API.
Modeling is the process of creating 3D models. One way is to represent the 3D model as points in 3D space. Each point, or vertex, has 3 coordinates: an X, an Y, and a Z coordinate, to define its location in 3D space. A pair of vertices can be connected by an edge, and edges bound polygons called faces. These faces define the surface of the model. Modeling is all about creating these sets of vertices, edges, and faces.
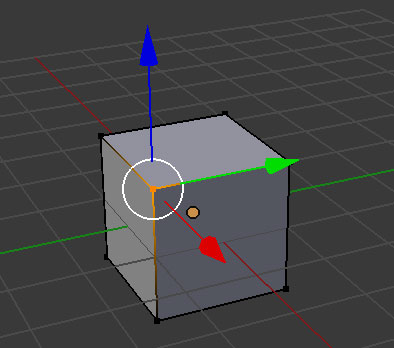
To create a model, we usually start with a primitive shape (like a sphere or a cube) and reshape it into what we’d like. Individual vertices, edges, and faces can be repositioned. New vertices, edges, and faces can be added to the basic model through simple operations. Two common ones are extrusion and subdivision.

Everyone is a beginner at something
Becoming confident with the fundamentals.

Choose your Learning Path. Our new Learning Paths will help you get where you want to go, whether it’s learning a programming language, developing new skills, or getting started with something entirely new.
I’ve noticed a curious thing about the term “beginner.” It’s acquired a sort of stigma — we seem to most often identify ourselves by what we’re an expert in, as if our burgeoning interests/talents have less value. An experienced PHP person who is just starting Python, for example, would rarely describe herself as a “Python Beginner” on a conference badge or biography. There are exceptions, of course, people eager to talk about what they’re learning; but, on the whole, it’s not something we see much.
I work on the Head First content, and first noticed it there. You suggest to a Java developer looking to learn Ruby that she check out our Head First Ruby. “But I know programming,” she’s likely to reply, “I’m not a beginner, I just need to learn Ruby.” People, by and large, buy into the stigma of being a “beginner,” which is, frankly, silly. Everyone is a beginner at something.

Learning programming at scale
Bringing some of the benefits of face-to-face learning to millions of people without access to an in-person tutor.
Millions of people around the world — from aspiring software engineers to data scientists — now want to learn programming. One of the best ways to learn is by working side-by-side with a personal tutor. A good tutor can watch you as you code, help you debug, explain tricky concepts on demand, and provide encouragement to keep you motivated. However, very few of us are lucky enough to have a tutor by our side. If we take a class, there might be 25 to 50 students for every teacher. If we take a MOOC (Massive Open Online Course), there might be 1,000 to 10,000 students for every professor or TA. And if we’re learning on our own from books or online tutorials, there’s no tutor or even fellow learners in sight. Given this reality, how can computer-based tools potentially bring some of the benefits of face-to-face learning to millions of people around the world who do not have access to an in-person tutor?
I’ve begun to address this question by building open-source tools to help people overcome a fundamental barrier to learning programming: understanding what happens as the computer runs each line of a program’s source code. Without this basic skill, it is impossible to start becoming fluent in any programming language. For example, if you’re learning Python, it might be hard to understand why running the code below produces the following three lines of output:
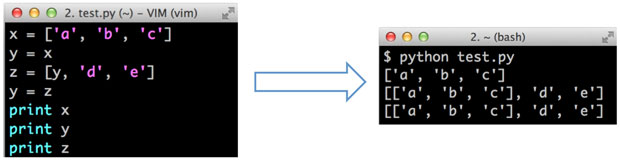
A tutor can explain why this code prints what it does by drawing the variables, data structures, and pointers at each execution step. However, what if you don’t have a personal tutor?
Four short links: 4 August 2015
Data-Flow Graphing, Realtime Predictions, Robot Hotel, and Open-Source RE
- Data-flow Graphing in Python (Matt Keeter) — not shared because data-flow graphing is sexy new hot topic that’s gonna set the world on fire (though, I bet that’d make Matt’s day), but because there are entire categories of engineering and operations migraines that are caused by not knowing where your data came from or goes to, when, how, and why. Remember Wirth’s “algorithms + data structures = programs”? Data flows seem like a different slice of “programs.” Perhaps “data flow + typos = programs”?
- Machine Learning for Sports and Real-time Predictions (Robohub) — podcast interview for your commute. Real time is gold.
- Japan’s Robot Hotel is Serious Business (Engadget) — hotel was architected to suit robots: For the porter robots, we designed the hotel to include wide paths.” Two paths slope around the hotel lobby: one inches up to the second floor, while another follows a gentle decline to guide first-floor guests (slowly, but with their baggage) all the way to their room. Makes sense: at Solid, I spoke to a chap working on robots for existing hotels, and there’s an entire engineering challenge in navigating an elevator that you wouldn’t believe.
- bokken — GUI to help open source reverse engineering for code.

Get started with functional programming in Python
Start writing shorter and less bug-prone Python code.

Download Functional Programming in Python.
It is hard to get a consistent opinion on just what functional programming is, even from functional programmers themselves. A story about elephants and blind men seems apropos here. Usually we can contrast functional programming with “imperative programming” (what you do in languages like C, Pascal, C++, Java, Perl, Awk, TCL, and most others, at least for the most part). Functional programming is not object-oriented programming (OOP), although some languages are both. And it is not Logic Programming (e.g., Prolog).
I would roughly characterize functional programming as having at least several of the following characteristics:
- Functions are first class (objects). That is, everything you can do with “data” can be done with functions themselves (such as passing a function to another function). Moreover, much functional programming utilizes “higher order” functions (in other words, functions that operate on functions that operate on functions).
- Functional languages eschew side effects. This excludes the almost ubiquitous pattern in imperative languages of assigning first one, then another value to the same variable to track the program state.
- In functional programming we focus not on constructing a data collection but rather on describing “what” that data collection consists of. When one simply thinks, “Here’s some data, what do I need to do with it?” rather than the mechanism of constructing the data, more direct reasoning is often possible.
Functional programming often makes for more rapidly developed, shorter, and less bug-prone code. Moreover, high theorists of computer science, logic, and math find it a lot easier to prove formal properties of functional languages and programs than of imperative languages and programs.
4 ways the Raspberry Pi is being used in education
Get inspired to create, teach, and learn with the Raspberry Pi.

The Raspberry Pi is a small computer that can be used for a variety of projects, and has been heralded as a great boon to education due to its flexibility and simplicity. While PcPro magazine noted in January of 2014 that Pi’s were “gathering dust” in classrooms, production has not ceased. The usage map is pretty impressive and the Raspberry Pi 2 was recently released.
In February of this year, the Raspberry Pi Foundation announced that they’re starting a mentoring program for people 16-21 years old. Here are four other ways that the Pi is being used in education and growing the tech community.

Learn a C-style language
Improve your odds with the lingua franca of computing.

You have a lot of choices when you’re picking a programming language to learn. If you look around the web development world, you’ll see a lot of JavaScript. At universities and high schools, you’ll often find Python used as a teaching language. If you go to conferences with language theorists, like Strange Loop, you’ll hear a lot about functional languages, such as Haskell, Scala, and Erlang. This level of choice is good: many languages mean that the overall state of the field is continually evolving, and coming up with new solutions. That choice also leads to a certain amount of confusion regarding what you should learn. It’s not possible to learn every language out there, even if you wanted to. Depending on the area you’re in, the choice of language may be made for you. For the overall health of your career, and to provide you the widest range of future opportunities, the single most useful language-related thing you can do is learn a C-style language.
A boring old C-style language just like millions of developers learned before you, going back to the 1980s and earlier. It’s not flashy, it’s usually not cutting edge, but it is smart. Even if you don’t stick with it, or program in it on a daily basis, having a C-style language in your repertoire is a no-brainer if you want to be taken seriously as a developer.
Read more…