

- 1996 vs 2011 Infographic from Online University (Evolving Newsroom) — “AOL and Yahoo! may be the butt of jokes for young people, but both are stronger than ever in the Internet’s Top 10”. Plus ça change, plus c’est la même chose.
- Pandas — open source Python package for data analysis, fast and powerful. (via Joshua Schachter)
- The Society of Mind — MIT open courseware for the classic Marvin Minsky theory that explains the mind as a collection of simpler processes. The subject treats such aspects of thinking as vision, language, learning, reasoning, memory, consciousness, ideals, emotions, and personality. Ideas incorporate psychology, artificial intelligence, and computer science to resolve theoretical issues such as whole vs. parts, structural vs. functional descriptions, declarative vs. procedural representations, symbolic vs. connectionist models, and logical vs. common-sense theories of learning. (via Maria Popover)
- Gamers Solve Problem in AIDS Research That Puzzled Scientists for Years (Ed Yong) — researchers put a key protein from an HIV-related virus onto the Foldit game. If we knew where the halves joined together, we could create drugs that prevented them from uniting. But until now, scientists have only been able to discern the structure of the two halves together. They have spent more than ten years trying to solve structure of a single isolated half, without any success. The Foldit players had no such problems. They came up with several answers, one of which was almost close to perfect. In a few days, Khatib had refined their solution to deduce the protein’s final structure, and he has already spotted features that could make attractive targets for new drugs. Foldit is a game where players compete to find the best shape for a protein, but it’s capable of being played by anyone–barely an eighth of players work in science.
"artificial intelligence" entries

Small brains, big data
How neuroscience is benefiting from distributed computing — and how computing might learn from neuroscience.
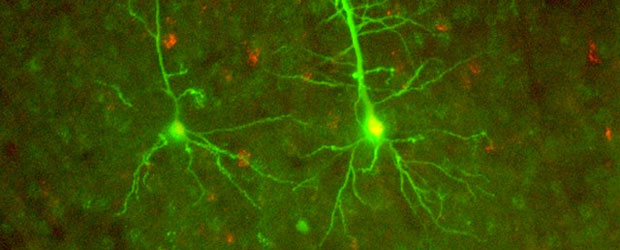
When we think about big data, we usually think about the web: the billions of users of social media, the sensors on millions of mobile phones, the thousands of contributions to Wikipedia, and so forth. Due to recent innovations, web-scale data can now also come from a camera pointed at a small, but extremely complex object: the brain. New progress in distributed computing is changing how neuroscientists work with the resulting data — and may, in the process, change how we think about computation. Read more…

In search of a model for modeling intelligence
True artificial intelligence will require rich models that incorporate real-world phenomena.

An orrery, a runnable model of the solar system that allows us to make predictions. Photo: Wikimedia Commons.
In my last post, we saw that AI means a lot of things to a lot of people. These dueling definitions each have a deep history — ok fine, baggage — that has massed and layered over time. While they’re all legitimate, they share a common weakness: each one can apply perfectly well to a system that is not particularly intelligent. As just one example, the chatbot that was recently touted as having passed the Turing test is certainly an interlocutor (of sorts), but it was widely criticized as not containing any significant intelligence.
Let’s ask a different question instead: What criteria must any system meet in order to achieve intelligence — whether an animal, a smart robot, a big-data cruncher, or something else entirely? Read more…
AI’s dueling definitions
Why my understanding of AI is different from yours.

SoftBank’s Pepper, a humanoid robot that takes its surroundings into consideration.
Editor’s note: this post is part of our Intelligence Matters investigation.
Let me start with a secret: I feel self-conscious when I use the terms “AI” and “artificial intelligence.” Sometimes, I’m downright embarrassed by them.
Before I get into why, though, answer this question: what pops into your head when you hear the phrase artificial intelligence?
For the layperson, AI might still conjure HAL’s unblinking red eye, and all the misfortune that ensued when he became so tragically confused. Others jump to the replicants of Blade Runner or more recent movie robots. Those who have been around the field for some time, though, might instead remember the “old days” of AI — whether with nostalgia or a shudder — when intelligence was thought to primarily involve logical reasoning, and truly intelligent machines seemed just a summer’s work away. And for those steeped in today’s big-data-obsessed tech industry, “AI” can seem like nothing more than a high-falutin’ synonym for the machine-learning and predictive-analytics algorithms that are already hard at work optimizing and personalizing the ads we see and the offers we get — it’s the term that gets trotted out when we want to put a high sheen on things. Read more…
Untapped opportunities in AI
Some of AI's viable approaches lie outside the organizational boundaries of Google and other large Internet companies.
Editor’s note: this post is part of an ongoing series exploring developments in artificial intelligence.
Here’s a simple recipe for solving crazy-hard problems with machine intelligence. First, collect huge amounts of training data — probably more than anyone thought sensible or even possible a decade ago. Second, massage and preprocess that data so the key relationships it contains are easily accessible (the jargon here is “feature engineering”). Finally, feed the result into ludicrously high-performance, parallelized implementations of pretty standard machine-learning methods like logistic regression, deep neural networks, and k-means clustering (don’t worry if those names don’t mean anything to you — the point is that they’re widely available in high-quality open source packages).
Google pioneered this formula, applying it to ad placement, machine translation, spam filtering, YouTube recommendations, and even the self-driving car — creating billions of dollars of value in the process. The surprising thing is that Google isn’t made of magic. Instead, mirroring Bruce Scheneier’s surprised conclusion about the NSA in the wake of the Snowden revelations, “its tools are no different from what we have in our world; it’s just better funded.” Read more…
“It works like the brain.” So?
There are many ways a system can be like the brain, but only a fraction of these will prove important.
Editor’s note: this post is part of an ongoing series exploring developments in artificial intelligence.
Here’s a fun drinking game: take a shot every time you find a news article or blog post that describes a new AI system as working or thinking “like the brain.” Here are a few to start you off with a nice buzz; if your reading habits are anything like mine, you’ll never be sober again. Once you start looking for this phrase, you’ll see it everywhere — I think it’s the defining laziness of AI journalism and marketing.
Surely these claims can’t all be true? After all, the brain is an incredibly complex and specific structure, forged in the relentless pressure of millions of years of evolution to be organized just so. We may have a lot of outstanding questions about how it works, but work a certain way it must. Read more…

Robots will remain forever in the future
As robots integrate more and more into our lives, they'll simply become part of normal, everyday reality — like dishwashers.
(Note: this post first appeared on Forbes; this lightly edited version is re-posted here with permission.)
We’ve watched the rising interest in robotics for the past few years. It may have started with the birth of FIRST Robotics competitions, continued with the iRobot and the Roomba, and more recently with Google’s driverless cars. But in the last few weeks, there has been a big change. Suddenly, everybody’s talking about robots and robotics.
It might have been Jeff Bezos’ remark about using autonomous drones to deliver products by air. It’s a cool idea, though I think it’s farfetched, but that’s another story. Amazon Prime isn’t Amazon’s first venture into robotics: a year and a half ago, they bought Kiva Systems, which builds robots that Amazon uses in their massive warehouses. (Personally, I think package delivery by drone is unlikely for many, many reasons, but that’s another story, and certainly no reason for Amazon not to play with delivery in their labs.)
But what really lit the fire was Google’s acquisition of Boston Dynamics, a DARPA contractor that makes some of the most impressive mobile robots anywhere. It’s hard to watch their videos without falling in love with what their robots can do. Or becoming very scared. Or both. And, of course, Boston Dynamics isn’t a one-time buy. It’s the most recent in a series of eight robotics acquisitions, and I’d bet that it’s not the last in the series. Read more…

The Amazon whisperer, invisible interfaces, FDA vs 23andMe, and robots usher in a new polical order
A backchannel look at what's on our radar.
The Radar team does a lot of sharing in the backchannel. Here’s a look at a selection of stories and innovative people and companies from around the web that have caught our recent attention. Have an interesting tidbit to contribute to the conversation? Send me an email or ping me on Twitter
- The edges of connected realities — Steve Mason’s TEDxSF talk, in which he discusses the evolution of connected environments and quotes Yves Behar: “The interface of the future is invisible.” (Jenn Webb, via Jim Stogdill, via Rachel Kalmar) Mason’s talk is a must-watch, so I’ll just provide direct access:

Linking open data to augmented intelligence and the economy
Nigel Shadbolt on AI, ODI, and how personal, open data could empower consumers in the 21st century.
After years of steady growth, open data is now entering into public discourse, particularly in the public sector. If President Barack Obama decides to put the White House’s long-awaited new open data mandate before the nation this spring, it will finally enter the mainstream.
As more governments, businesses, media organizations and institutions adopt open data initiatives, interest in the evidence behind release and the outcomes from it is similarly increasing. High hopes abound in many sectors, from development to energy to health to safety to transportation.
“Today, the digital revolution fueled by open data is starting to do for the modern world of agriculture what the industrial revolution did for agricultural productivity over the past century,” said Secretary of Agriculture Tom Vilsack, speaking at the G-8 Open Data for Agriculture Conference.
As other countries consider releasing their public sector information as data and machine-readable formats onto the Internet, they’ll need to consider and learn from years of effort at data.gov.uk, data.gov in the United States, and Kenya in Africa.
 One of the crucial sources of analysis for the success or failure of open data efforts will necessarily be research institutions and academics. That’s precisely why research from the Open Data Institute and Professor Nigel Shadbolt (@Nigel_Shadbolt) will matter in the months and years ahead.
One of the crucial sources of analysis for the success or failure of open data efforts will necessarily be research institutions and academics. That’s precisely why research from the Open Data Institute and Professor Nigel Shadbolt (@Nigel_Shadbolt) will matter in the months and years ahead.
In the following interview, Professor Shadbolt and I discuss what lies ahead. His responses were lightly edited for content and clarity.
Read more…

Four short links: 19 September 2011
The Changing Internet, Python Data Analysis, Society of Mind, and Gaming Proteins
Four short links: 24 June 2011
Eliza Aftermath, Open Textbook, Crowdsourcing Music Fingerprinting, Singularity Skepticism
- Eliza pt 3 — delightful recapitulation of the reaction to Eliza and Weizenbaum’s reaction to that reaction, including his despair over the students he taught at MIT. Weizenbaum wrote therein of his students at MIT, which was of course all about science and technology. He said that they “have already rejected all ways but the scientific to come to know the world, and [they] seek only a deeper, more dogmatic indoctrination in that faith (although that word is no longer in their vocabulary).”
- Computer Vision Models — textbook written in the open for public review. (via Hacker News)
- Echoprint — open source and open data music fingerprinting service from MusicBrainz and others. I find it interesting that doing something new with music data requires crowdsourcing because nobody has the full set.
- Three Arguments Against The Singularity (Charlie Stross) — We clearly want machines that perform human-like tasks. We want computers that recognize our language and motivations and can take hints, rather than requiring instructions enumerated in mind-numbingly tedious detail. But whether we want them to be conscious and volitional is another question entirely. I don’t want my self-driving car to argue with me about where we want to go today. I don’t want my robot housekeeper to spend all its time in front of the TV watching contact sports or music videos. And I certainly don’t want to be sued for maintenance by an abandoned software development project.