- Announcing Otto — new Hashicorp tool that automatically builds development environments without any configuration; it can detect your project type and has built-in knowledge of industry-standard tools to setup a development environment that is ready to go. When you’re ready to deploy, Otto builds and manages an infrastructure, sets up servers, builds, and deploys the application.
- The Majority Illusion in Social Networks (arxiv) — if connectors do something, it’s perceived as more popular than if the same number of “unpopular” people in the social graph do it. (via MIT TR)
- Scientist Says Researcher in Immigrant-Friendly Countries Can’t Use His Software — software to build phylogenetic trees, but the author’s a loon. It’s another sign that it’s unwise to do science with non-free software.
- Orchestra — an open source system to orchestrate teams of experts and machines on complex projects.
"automation" entries

Boost your career with new levels of automation
Elevate automation through orchestration.

As sysadmins we have been responsible for running applications for decades. We have done everything to meet demanding SLAs including “automating all the things” and even trading sleep cycles to recuse applications from production fires. While we have earned many battle scars and can step back and admire fully automated deployment pipelines, it feels like there has always been something missing. Our infrastructure still feels like an accident waiting to happen and somehow, no matter how much we manage to automate, the expense of infrastructure continues to increase.
The root of this feeling comes from the fact that many of our tools don’t provide the proper insight into what’s really going on and require us to reverse engineer applications in order to effectively monitor them and recover from failures. Today many people bolt on monitoring solutions that attempt to probe applications from the outside and report “health” status to a centralized monitoring system, which seems to be riddled with false alarms or a list of alarms that are not worth looking into because there is no clear path to resolution.
What makes this worse is how we typically handle common failure scenarios such as node failures. Today many of us are forced to statically assign applications to machines and manage resource allocations on a spreadsheet. It’s very common to assign a single application to a VM to avoid dependency conflicts and ensure proper resource allocations. Many of the tools in our tool belt have be optimized for this pattern and the results are less than optimal. Sure this is better than doing it manually, but current methods are resulting in low resource utilization, which means our EC2 bills continue to increase — because the more you automate, the more things people want to do.
How do we reverse course on this situation? Read more…

Four short links: 2 October 2015
Automatic Environments, Majority Illusion, Bogus Licensing, and Orchestrating People and Machines

Avoid design pitfalls in the IoT: Keep the focus on people
The O'Reilly Radar Podcast: Robert Brunner on IoT pitfalls, Ammunition, and the movement toward automation.
Subscribe to the O’Reilly Radar Podcast to track the technologies and people that will shape our world in the years to come.

For this week’s Radar Podcast, I had the opportunity to sit down with Robert Brunner, founder of the Ammunition design studio. Brunner talked about how design can help mitigate IoT pitfalls, what drove him to found Ammunition, and why he’s fascinated with design’s role in the movement toward automation.
Here are a few of the highlights from our chat:
One of the biggest pitfalls I’m seeing in how companies are approaching the Internet of Things, especially in the consumer market, is, literally, not paying attention to people — how people understand products and how they interact with them and what they mean to them.
It was this broader experience and understanding of what [a product] is and what it does in people’s lives, and what it means to them — that’s experienced not just through the thing, but how they learn about it, how they buy it, what happens when they open up the box, what happens when they use the product, what happens when the product breaks; all these things add up to how you feel about it and, ultimately, how you relate to a company. That was the foundation of [Ammunition].
Ultimately, I define design as the purposeful creation of things.

The importance of orchestration in transforming legacy IT
How orchestration differs from automation in the enterprise cloud.

Buy The Enterprise Cloud.
The orchestration of workflow processes is an essential part of cloud computing. Without orchestration, many of the benefits and characteristics of cloud computing cannot be achieved at the price point that cloud services should be offered. Failure to automate as many processes as possible results in higher personnel labor costs, slower time to deliver the new service to customers, and ultimately higher cost with less reliability.
What is meant by automation? Automation is technique used in traditional data centers —and critical in a cloud environment — to install software or initiate other activities. Traditional IT administrators use sequential scripts to perform a series of tasks (e.g. software installation or configuration); however, this is now considered an antiquated technique in a modern cloud-based environment. Orchestration differs from automation in that it does not rely entirely on static sequential scripts but rather sophisticated workflows; multiple automated threads; query-based and if/then logic; object-oriented and topology workflows; and even the ability to back-out a series of automated commands if necessary.
Orchestration can best be explained through a typical use case example of a customer placing an order within their cloud service web-portal, and following the steps necessary to bring the service online. The actions below illustrate a very high level scenario where the cloud management software performs the orchestration:

Ghosts in the machines
The secret to successful infrastructure automation is people.

“The trouble with automation is that it often gives us what we don’t need at the cost of what we do.” —Nicholas Carr, The Glass Cage: Automation and Us
Virtualization and cloud hosting platforms have pervasively decoupled infrastructure from its underlying hardware over the past decade. This has led to a massive shift towards what many are calling dynamic infrastructure, wherein infrastructure and the tools and services used to manage it are treated as code, allowing operations teams to adopt software approaches that have dramatically changed how they operate. But with automation comes a great deal of fear, uncertainty and doubt.
Common (mis)perceptions of automation tend to pop up at the extreme ends: It will either liberate your people to never have to worry about mundane tasks and details, running intelligently in the background, or it will make SysAdmins irrelevant and eventually replace all IT jobs (and beyond). Of course, the truth is very much somewhere in between, and relies on a fundamental rethinking of the relationship between humans and automation.
Read more…
Four short links: 19 February 2015
Magical Interfaces, Automation Tax, Cyber Manhattan Project, and US Chief Data Scientist
- MAS S66: Indistinguishable From… Magic as Interface, Technology, and Tradition — MIT course taught by Greg Borenstein and Dan Novy. Further, magic is one of the central metaphors people use to understand the technology we build. From install wizards to voice commands and background daemons, the cultural tropes of magic permeate user interface design. Understanding the traditions and vocabularies behind these tropes can help us produce interfaces that use magic to empower users rather than merely obscuring their function. With a focus on the creation of functional prototypes and practicing real magical crafts, this class combines theatrical illusion, game design, sleight of hand, machine learning, camouflage, and neuroscience to explore how ideas from ancient magic and modern stage illusion can inform cutting edge technology.
- Maybe We Need an Automation Tax (RoboHub) — rather than saying “automation is bad,” move on to “how do we help those displaced by automation to retrain?”.
- America’s Cyber-Manhattan Project (Wired) — America already has a computer security Manhattan Project. We’ve had it since at least 2001. Like the original, it has been highly classified, spawned huge technological advances in secret, and drawn some of the best minds in the country. We didn’t recognize it before because the project is not aimed at defense, as advocates hoped. Instead, like the original, America’s cyber Manhattan Project is purely offensive. The difference between policemen and soldiers is that one serves justice and the other merely victory.
- White House Names DJ Patil First US Chief Data Scientist (Wired) — There is arguably no one better suited to help the country better embrace the relatively new discipline of data science than Patil.

What is DevOps (yet again)?
Empathy, communication, and collaboration across organizational boundaries.

I might try to define DevOps as the movement that doesn’t want to be defined. Or as the movement that wants to evade the inevitable cargo-culting that goes with most technical movements. Or the non-movement that’s resisting becoming a movement. I’ve written enough about “what is DevOps” that I should probably be given an honorary doctorate in DevOps Studies.
Baron Schwartz (among others) thinks it’s high time to have a definition, and that only a definition will save DevOps from an identity crisis. Without a definition, it’s subject to the whims of individual interest groups, and ultimately might become a movement that’s defined by nothing more than the desire to “not be like them.” Dave Zwieback (among others) says that the lack of a definition is more of a blessing than a curse, because it “continues to be an open conversation about making our organizations better.” Both have good points. Is it possible to frame DevOps in a way that preserves the openness of the conversation, while giving it some definition? I think so.
DevOps started as an attempt to think long and hard about the realities of running a modern web site, a problem that has only gotten more difficult over the years. How do we build and maintain critical sites that are increasingly complex, have stringent requirements for performance and uptime, and support thousands or millions of users? How do we avoid the “throw it over the wall” mentality, in which an operations team gets the fallout of the development teams’ bugs? How do we involve developers in maintenance without compromising their ability to release new software?
New opportunities in the maturing marketplace of big data components
The evolving marketplace is making new data applications and interactions possible.
Editor’s note: this is an excerpt from our new report Data: Emerging Trends and Technologies, by Alistair Croll. Download the free report here.
Here’s a look at some options in the evolving, maturing marketplace of big data components that are making the new applications and interactions we’ve been looking at possible.
Graph theory
First used in social network analysis, graph theory is finding more and more homes in research and business. Machine learning systems can scale up fast with tools like Parameter Server, and the TitanDB project means developers have a robust set of tools to use.
Are graphs poised to take their place alongside relational database management systems (RDBMS), object storage, and other fundamental data building blocks? What are the new applications for such tools?
Inside the black box of algorithms: whither regulation?
It’s possible for a machine to create an algorithm no human can understand. Evolutionary approaches to algorithmic optimization can result in inscrutable, yet demonstrably better, computational solutions.
If you’re a regulated bank, you need to share your algorithms with regulators. But if you’re a private trader, you’re under no such constraints. And having to explain your algorithms limits how you can generate them.
As more and more of our lives are governed by code that decides what’s best for us, replacing laws, actuarial tables, personal trainers, and personal shoppers, oversight means opening up the black box of algorithms so they can be regulated.
Years ago, Orbitz was shown to be charging web visitors who owned Apple devices more money than those visiting via other platforms, such as the PC. Only that’s not the whole story: Orbitz’s machine learning algorithms, which optimized revenue per customer, learned that the visitor’s browser was a predictor of their willingness to pay more. Read more…

If it weren’t for the people…
A humanist approach to automation.
 Editor’s note: At some point, we’ve all read the accounts in newspapers or on blogs that “human error” was responsible for a Twitter outage, or worse, a horrible accident. Automation is often hailed as the heroic answer, poised to eliminate the specter of human error. This guest post from Steven Shorrock, who will be delivering a keynote speech at Velocity in Barcelona, exposes human error as dangerous shorthand. The more nuanced way through involves systems thinking, marrying the complex fabric of humans and the machines we work with every day.
Editor’s note: At some point, we’ve all read the accounts in newspapers or on blogs that “human error” was responsible for a Twitter outage, or worse, a horrible accident. Automation is often hailed as the heroic answer, poised to eliminate the specter of human error. This guest post from Steven Shorrock, who will be delivering a keynote speech at Velocity in Barcelona, exposes human error as dangerous shorthand. The more nuanced way through involves systems thinking, marrying the complex fabric of humans and the machines we work with every day.
In Kurt Vonnegut’s dystopian novel ‘Player Piano’, automation has replaced most human labour. Anything that can be automated, is automated. Ordinary people have been robbed of their work, and with it purpose, meaning and satisfaction, leaving the managers, scientists and engineers to run the show. Dr Paul Proteus is a top manager-engineer at the head of the Ilium Works. But Proteus, aware of the unfairness of the situation for the people on the other side of the river, becomes disillusioned with society and has a moral awakening. In the penultimate chapter, Paul and his best friend Finnerty, a brilliant young engineer turned rogue-rebel, reminisce sardonically: “If only it weren’t for the people, the goddamned people,” said Finnerty, “always getting tangled up in the machinery. If it weren’t for them, earth would be an engineer’s paradise.”

Smarter buildings through data tracking
Buildings are ready to be smart — we just need to collect and monitor the data.
Buildings, like people, can benefit from lessons built up over time. Just as Amazon.com recommends books based on purchasing patterns or doctors recommend behavior change based on what they’ve learned by tracking thousands of people, a service such as Clockworks from KGS Buildings can figure out that a boiler is about to fail based on patterns built up through decades of data.
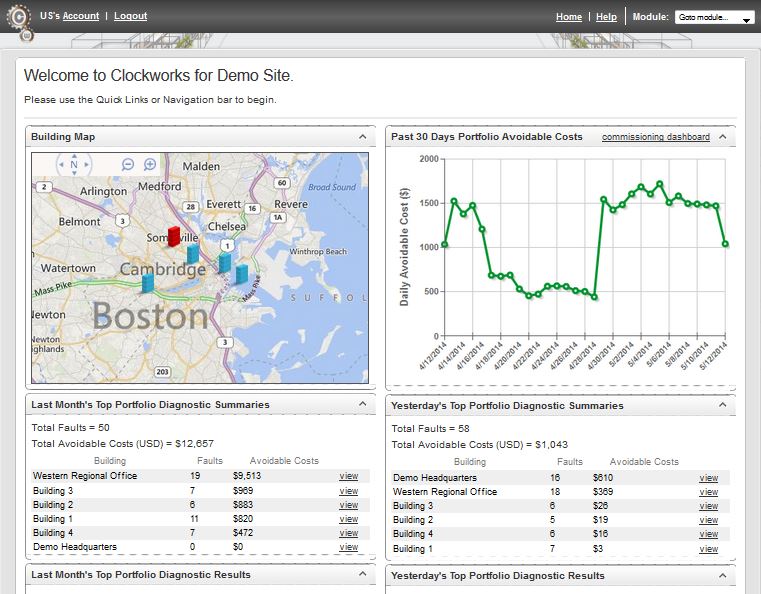
Screen shot from KGS Clockworks analytics tool
I had the chance to be enlightened about intelligent buildings through a conversation with Nicholas Gayeski, cofounder of KGS Buildings, and Mark Pacelle, an engineer with experience in building controls who has written for O’Reilly about the Internet of Things. Read more…